BigQueryMLの2値分類のチュートリアルをやってみた 01
はじめに
BigQuery MLのチュートリアルを進めるうえで困ったところや追加で調べたところを作業メモとして残します(必要に応じて本家のドキュメントにフィードバックは送っております)。
ステップ2のデータの確認の補足
https://cloud.google.com/bigquery-ml/docs/logistic-regression-prediction#run_the_query
データ確認のところで下記のクエリを投稿しています。
SELECT
age,
workclass,
marital_status,
education_num,
occupation,
hours_per_week,
income_bracket
FROM
`bigquery-public-data.ml_datasets.census_adult_income`
LIMIT
100;ただそのQueryの結果の説明を読んでいるとeducationとfunctional_weightカラムの説明がでてきます。 Queryの中で上記2つのカラムを指定していないのでなんのことを指しているのかここだけではわからなかったので、 下記のクエリに修正して実行しました。
SELECT
age,
workclass,
marital_status,
education_num,
occupation,
hours_per_week,
income_bracket,
education,
functional_weight
FROM
`bigquery-public-data.ml_datasets.census_adult_income`
LIMIT
100;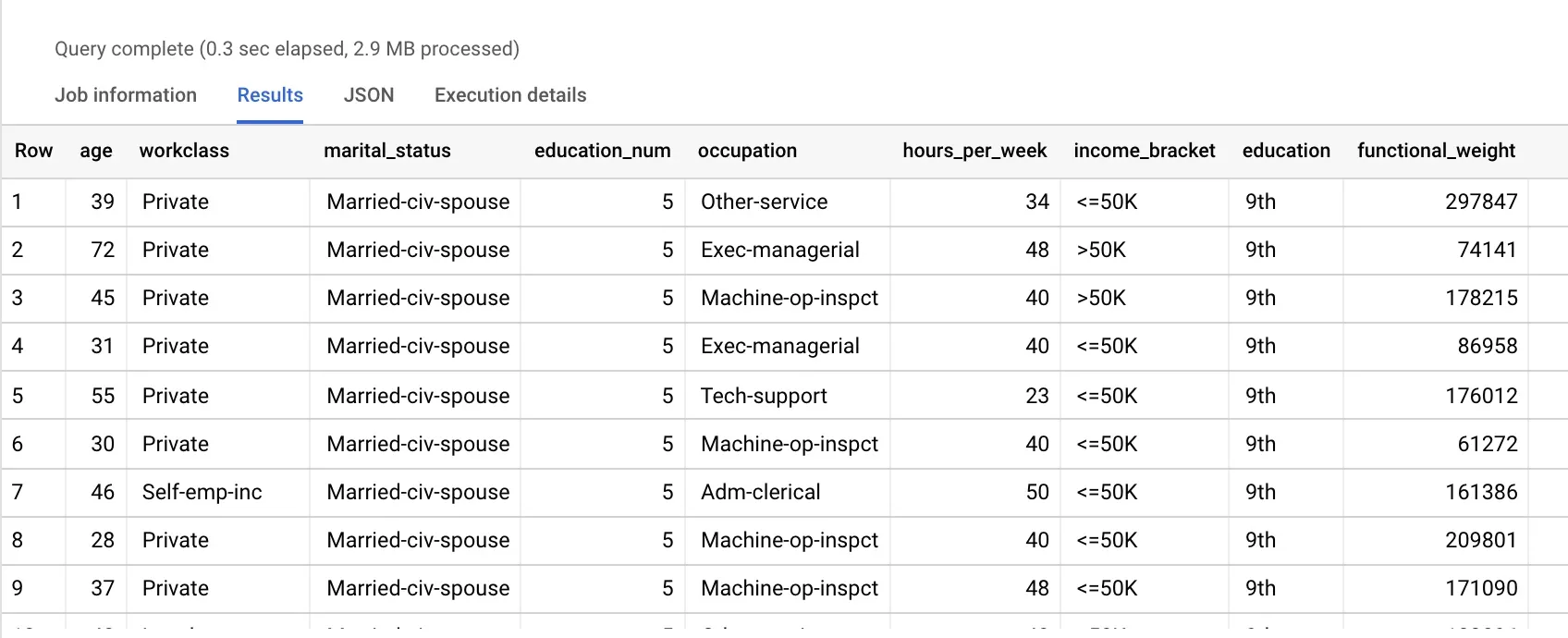
修正したQueryの実行結果は上記です。 こちらからeducationとeducation_numが同じことを示すだけで、別々の表現になっていることを指摘していましたが educationカラムで確かに同じであることが伺えます。 ただ、すべての行で同じかどうか念の為確認したいと思い、下記のSQLを動かして確認しました。
SELECT
education,
education_num,
count(*)
FROM
`bigquery-public-data.ml_datasets.census_adult_income`
GROUP BY
education,
education_num
;こちらから得られる結果を確認するとたしかにeducationとeducation_numの結果は1:1対応しており、 educationの1つの値がeducation_numに2回使われることがありませんでした。もちろん逆も同様でした。
ステップ3の学習データのtraining, evaluation, predictionの比率
https://cloud.google.com/bigquery-ml/docs/logistic-regression-prediction#run_the_query_2
ここでの説明が学習データとして80%使い、評価用10%、予測用10%として扱う記載ありますが、実際にどれほどの比率か確認したいと思います。
SELECT
dataframe,
COUNT(*) AS dataframe_num,
COUNT(*) / MAX(a.total) AS ratio
FROM
`census.input_view`,
(
SELECT
COUNT(*) AS total
FROM
`census.input_view` ) a
GROUP BY
dataframe
;こちらが各比率を計算するために使ったSQLです。その結果が下記になります。
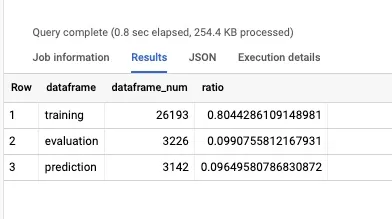
おおまかにみると想定どおり8:1:1になっていることを確認できました。
まとめ
もっと効率的なQueryの書き方があるかもしれないです…。
続き
続きはこちらですの続きです。)
参考
https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create