モデルモニタリングとして利用できる Whylogs の概要
この記事は MLOps Advent Calendar 2022 にリンクしてます。
MLOps にカテゴライズされる機能はいくつかありますが、その中のひとつに機械学習のモデルモニタリングがあります。 この記事ではモデルモニタリングツールとして適用可能な Whylogs の概要と触ってみた感想をまとめます。
TL;DR
- モデルの監視におけるツールである Whylogs は主にテーブル、画像、文字のデータタイプの可視化や設定したデータの条件(制約)を満たしているか確認が可能です。
- Whylab という無料/有料 SaaS サービスを使うことでより多くの機能が使えるが、pandas をベースに無料でも特徴量の差分などの可視化が行えます。
Whylogs とは?
WhyLabs Inc. 社のデータロギングに関するオープンソースが Whylogs がのようです。 Github リンク 2022/12/18 現在のGithub上の指標は下記になります。
| watch | folk | star | 初回リリース | 2022 / 12 / 18 現在の最新リリース |
|---|---|---|---|---|
| 28 | 86 | 1,934 | 2020/9/23 | 2022/12/14 |
- prereleaseを除く
Star 数は昨年リリースしたことを考えると MLOps 界隈ではまぁまぁなのでは?と最初思ったのですが、 同じ機械学習のモニタリングツールである OSS の Evidently AI は今年リリース(プレリリースを除く)で、 star 数が 2983 (2022/12/18現在) なので盛り上げは Evidently AI のほうが多いかなと思います。できることが違うので単純な比較をしたらいけないかなとは思いますが参考までに。
Whylogs ができることを本家のページを非公式に翻訳すると以下ができるようです。
- データセットの変更/変化をトラックできる
- Data Constraints を作成して、データの見た目が適切かどうかを確認することができる
- データセットに関する主要な統計情報を迅速に可視化することができる
ちなみに日本企業で使っているところがないか Google 検索でしらべたところ下記の記事を見つけました。
リンク : MLOpsを支えるヤフー独自のモデルモニタリングサービス, Yahoo Japan
Iris のデータを使ってモニタリングしてみる
実際に Iris のデータをもちいて Whylogsの基本的な使い方を見てみます。
Constraints
import whylogs as why
import pandas as pd
from whylogs.core.constraints import Constraints, ConstraintsBuilder
from whylogs.core.constraints.factories import greater_than_number
col_names = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width','Species']
df = pd.read_csv("iris.csv", header=None, names=col_names)
results = why.log(df)
profile_view = why.log(df).view()
builder = ConstraintsBuilder(profile_view)
builder.add_constraint(greater_than_number(column_name="Sepal_Length", number=0.0))
constraints = builder.build()
constraints.report()ある条件を設定してすべてみたすかどうか確認しています。この結果は文字として表示されますが Jupyter などをつかっている場合は下記プログラムを追加することで、Jupyter内で結果を確認できます。
from whylogs.viz import NotebookProfileVisualizer
visualization = NotebookProfileVisualizer()
visualization.constraints_report(constraints, cell_height=300) もちろん複数条件を設定が可能です。
もちろん複数条件を設定が可能です。
Visualize
特徴量の分布も pandas の dataframe にデータをいれていれば簡単に可視化できました。観測した数(表示したすべての特徴量とその数)、欠損数、平均、Min、Maxという基本的統計量が自動的に計算され、サンプルプログラムは下記です。
import whylogs as why
import pandas as pd
from whylogs.viz import NotebookProfileVisualizer
col_names = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width','Species']
df = pd.read_csv("iris.csv", header=None, names = col_names)
results = why.log(df)
profile_view = why.log(df).view()
visualization = NotebookProfileVisualizer()
visualization.set_profiles(target_profile_view=profile_view)
visualization.profile_summary()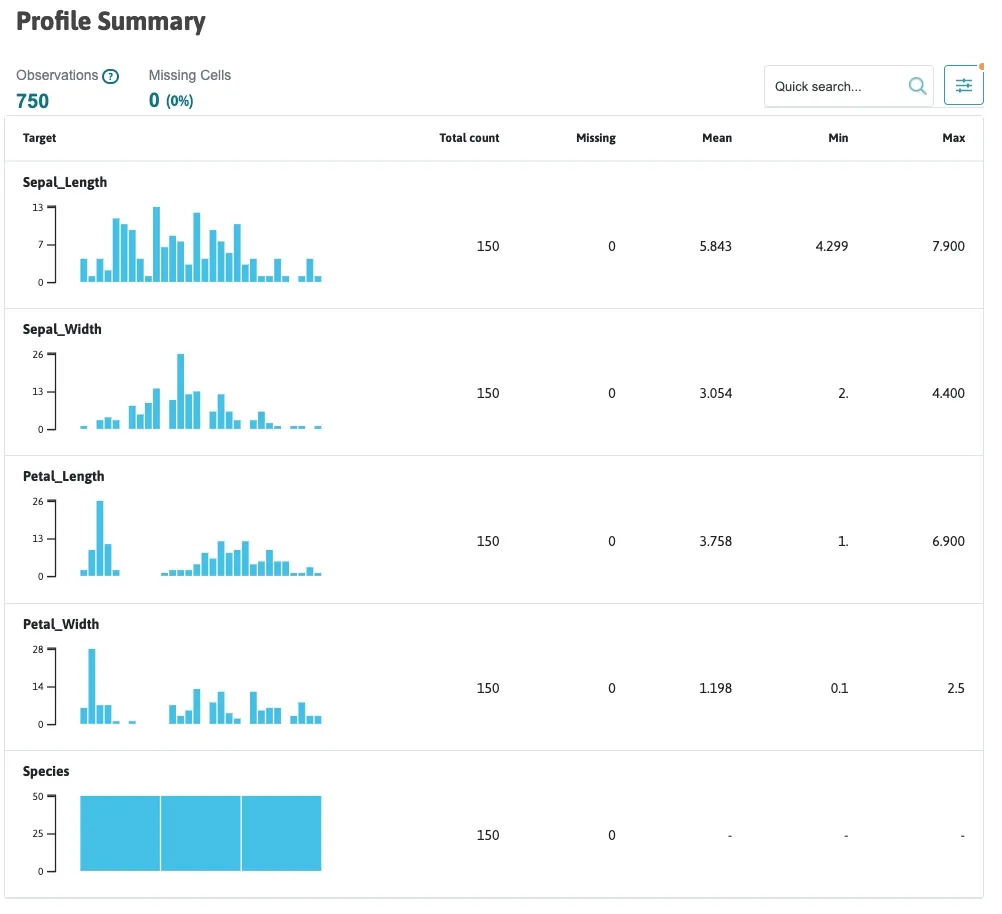
今度は2つの別々のグループ間で特徴量の分布を比較する場合の方法です。参照用の profile を用意して set_profiles を使用するときに参照先のデータを指定すれば表示できます。
import whylogs as why
import pandas as pd
from whylogs.viz import NotebookProfileVisualizer
col_names = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width','Species']
df = pd.read_csv("iris.csv", header=None, names = col_names)
df2 = df.sample(frac=0.4, random_state=0)
df3 = df.drop(df2.index)
profile_view = why.log(df2).view()
profile_view_ref = why.log(df3).view()
visualization = NotebookProfileVisualizer()
visualization.set_profiles(target_profile_view=profile_view, reference_profile_view=profile_view_ref)
visualization.summary_drift_report()さきほどの Iris のデータを 6:4 でわけて表示しました。さきほどの可視化したグラフと異なるのが、Reference となるオレンジの棒グラフと Drfit の表することができます。加えて、 Target と Refenrence のグラフの可視化だけでなく、定量的に比較できます。
ここでの比較する指標は Kolmogorov-Smirnov (KS) 検定を使っています。すでに用意されている閾値では、0.00-0.05 が drift, 0.05-0.15がdriftの可能性がある、0.15-1.0がdriftがないということを示しています。
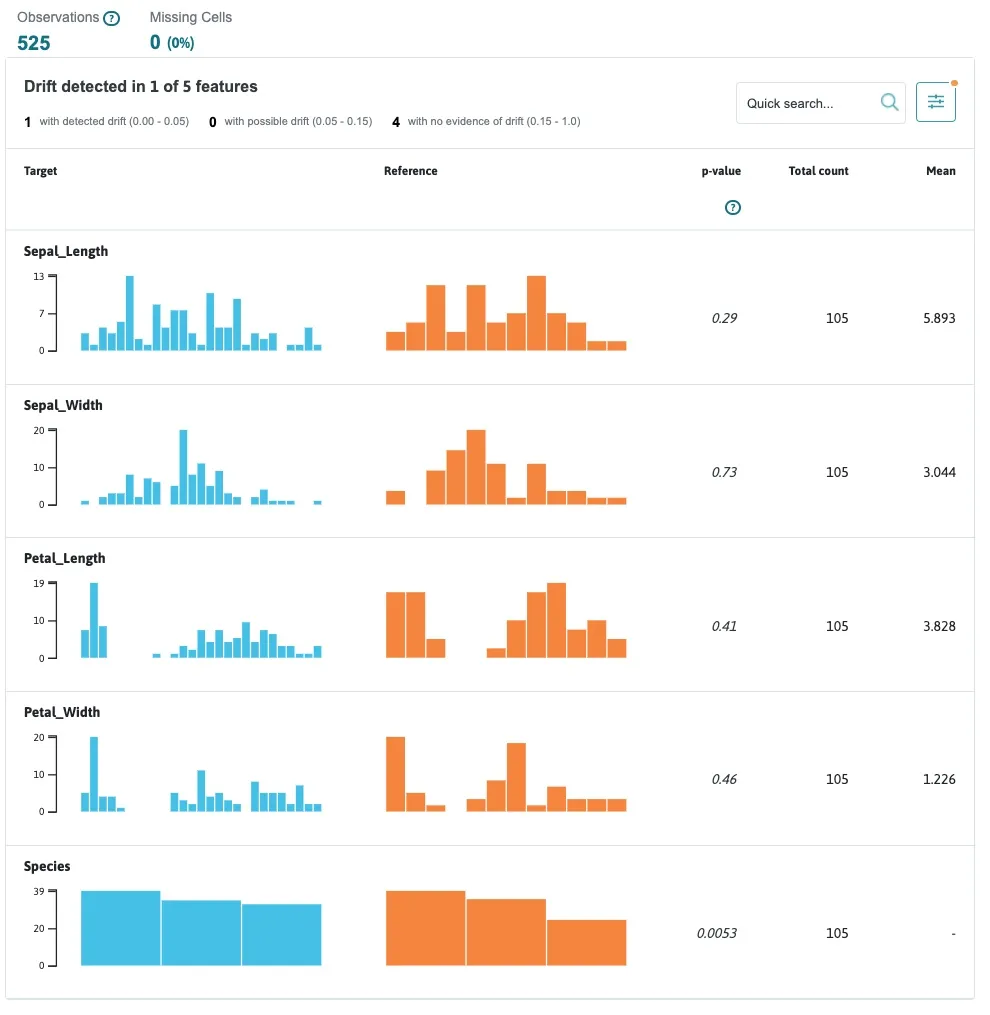
他の API で特徴量の四分位や統計量のサマリーとかも計算できそうです。 whylogs API
はまったところ
サンプルの Jupyter ファイルもあったのでコード自体はさくさくとできたのですがインストールが必要なのは whylog だけでなく、whylog の viz などサブライブラリのようなものをインストール必要があることに注意が必要です。
pip install "whylogs[viz]"おわり
pandas の DataFrame をつかって、 K-S testによる特徴量の分布変化をみたなどあれば用途としては使いやすいなと思いました。 ここではとりあげなかったですが画像の出力/保存する API も用意されているのでサーバーでの管理、ログの保存とかもできそうです。
この記事では実施しませんでしたが、Apache Spark, BigQuery, Dask… etc. などのデータソースが異なる場合のサンプルファイルも github にありました。これらのツールを本番環境で利用している方は使いやすいかもしれないです。 whylogs/python/examples
デモ動画を見る限りは SaaS に連携したほうが情報量が多くなったり可視化できる項目が増えるようですが、この記事ではフォローしませんのでもし興味があるかたは記事内のサイトなどをご確認ください。